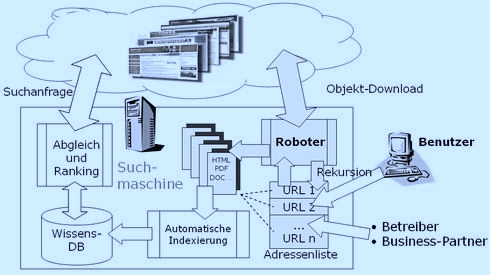
Suchmaschinen gelten heute als die vorherrschenden Informationssysteme. Sie passen sich einerseits dem Verhalten der Nutzer an, andererseits prägen sie auch dessen Informationsverhalten. Bedenklich wird dies an dem Punkt, wenn Nutzer all ihre Recherchen vorbehaltslos mit einer Suchmaschine durchführen, da diese mittels ihrer Rankingalgorithmen die Informationswahl, und somit auch die Wissensaneignung bestimmt. (Lewandowski 2013, S. 11)
Seitens der Benutzer besteht vorwiegend das Bild, dass sich mit Google sämtliche Informationen aus dem WWW auffinden lassen. (Lewandowski 2011, S. 1)
Ganz abgesehen davon, dass Suchmaschinen die Inhalte des „Deep Webs“ nicht erfassen, sind auch externe Einflüsse wie Suchmaschinenoptimierung (SEO), Werbetreffer, Verzerrungen und Monopolisierung des Marktes nicht zu unterschätzen. (Lewandowski 2013, S. 11 ff.)
Als wesentliche Herausforderungen der näheren Zukunft gelten die Einbindung von Invisible- Webcontent, der Umgang mit Paid Content, sowie die intuitive Benutzerführung. (Lewandowski 2013, S. 1)
Die Abdeckung der Webinhalte durch Suchmaschinen dürfte aber dennoch abnehmen, da die Anzahl konventioneller Webseiten (HTML, Standardformate) schneller wächst, als die Suchmaschinen indexieren können. Andererseits breitet sich das sogenannte „Deep Web“ mit einer extremen Geschwindigkeit aus. (Lewandowski 2011, S. 8) Besonders die umfangreichen Informationsangebote der traditionellen Informationsanbieter wie LexisNexis u.a. werden von traditionellen Suchmaschinen kaum erschlossen, wobei fragwürdig ist, ob kostenpflichtige Dokumente in das Raster der heutigen Suchdienste passen. (Griesbaum et al. 2004, S. 12 ff.)
Denkbar wären wohl hybride Suchmaschinen, welche sowohl frei zugängliche Dokumente, als auch kostenpflichtige Inhalte anbieten. Auch möglich wäre, dass die Anbieter der Inhalte die Suchdienste für eine gewählte Indexierung bezahlen (was teilweise auch schon gemacht wird). Ein weiterer Weg wäre den Suchmaschinen einen Volltext zur Indexierung vorzulegen, wobei der Nutzer vorerst nur ein Abstract auffinden kann und erst durch die Bezahlung auf den Volltext zugreifen kann. (dies geschieht zum Teil schon bei Google Scholar ) (Lewandowski 2011, S. 8)
Ich persönlich finde es fragwürdig, ob es wirklich nötig ist, dass Google auch auf die Inhalte des „Deep Webs“ zugreifen kann. Abgesehen von Filter Bubbles und dem Trend zur Personalisierung erscheint die Kritik, dass Google nicht die Qualität der traditionellen Suchdienste erreicht nicht wirklich praxisrelevant, da die meisten, welche Google für private Zwecke nutzen, ihre Bedürfnisse befriedigt sehen. Zudem würde die Hürde eine Suchmaschine zu bedienen über die Durchmischung von wissenschaftlichen, als auch „normalen“ Informationen möglichweise ansteigen. Vielmehr sollte es doch darum gehen, ein Bewusstsein dafür zu schaffen, dass es neben Google noch sehr viele andere Möglichkeiten gibt, so dass die Idee der Inhalte des WWW nicht auf die Suchergebnisse von Google reduziert wird. Möglicherweise liegt der Ansetzungspunkt zur Handlung nicht bei den Suchmaschinenbetreibern, sondern vielmehr bei der Informationskompetenz der Nutzer.